

2008년09월07일 93번
[고급통계처리및분석] 평균이 μ, 분산이 σ2인 분포로부터 크기 n인 확률표본 X1, …Xn을 얻었을 때 σ2에 대한 다음 두 추정량이 다음과 같다. 이들에 대한 설명으로 옳은 것은? (단, E는 기댓값, V는 분산, MSE는 평균제곱오차, Bias는 편향(편의)를 의미한다.)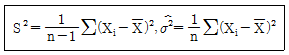
-
①
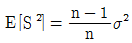
-
②
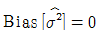
-
③
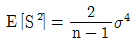
-
④
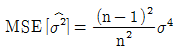
(정답률: 알수없음)
문제 해설
정답: ""
- 첫 번째 추정량은 편향이 없는 불편추정량이다. 이는 추정량의 기댓값이 모수와 같다는 것을 의미한다. 따라서 이 추정량은 모수를 잘 추정할 가능성이 높다.
- 두 번째 추정량은 편향이 있는 추정량이다. 이는 추정량의 기댓값이 모수와 다르다는 것을 의미한다. 따라서 이 추정량은 모수를 잘 추정할 가능성이 낮다.
- MSE는 추정량의 분산과 편향의 제곱의 합으로 정의된다. 따라서 MSE가 작을수록 추정량이 모수를 잘 추정한다는 것을 의미한다.
- 첫 번째 추정량의 MSE는 σ2/n으로, 두 번째 추정량의 MSE는 (n-1)σ2/n으로 계산된다. 따라서 첫 번째 추정량의 MSE가 두 번째 추정량의 MSE보다 작으므로, 첫 번째 추정량이 더 좋은 추정량이다.
"- 첫 번째 추정량은 편향이 없는 불편추정량이다. 이는 추정량의 기댓값이 모수와 같다는 것을 의미한다. 따라서 이 추정량은 모수를 잘 추정할 가능성이 높다.
- 두 번째 추정량은 편향이 있는 추정량이다. 이는 추정량의 기댓값이 모수와 다르다는 것을 의미한다. 따라서 이 추정량은 모수를 잘 추정할 가능성이 낮다.
- MSE는 추정량의 분산과 편향의 제곱의 합으로 정의된다. 따라서 MSE가 작을수록 추정량이 모수를 잘 추정한다는 것을 의미한다.
- 첫 번째 추정량의 MSE는 σ2/n으로, 두 번째 추정량의 MSE는 (n-1)σ2/n으로 계산된다. 따라서 첫 번째 추정량의 MSE가 두 번째 추정량의 MSE보다 작으므로, 첫 번째 추정량이 더 좋은 추정량이다.
연도별
진행 상황
0 오답
0 정답